Is my Data Complete? Or Why It’s Super Important to Have All Your Data?
Having everything filled out and correct in your data is super important for a bunch of reasons.
Let's break down why it matters so much:
- Making Smart Choices: When you've got all the info, you can make really smart choices because you're seeing the whole picture.
- Spotting the Patterns: If some info is missing, you might get the wrong idea about what's going on. With everything in place, it's way easier to spot the cool patterns that help you plan for the future.
- Really Good Data Analysis: Missing bits of data can mess up your analysis. If you have all the data, you can trust your findings way more.
- Mixing Data Together: You need all the pieces to put different sets of data together smoothly. If bits are missing, things just don't match up right.
- Following the Rules: Some jobs have super strict rules about keeping data complete. You need to make sure you don't miss anything to keep out of trouble.
- Top-Notch Data Quality: If your data is not all there, it's not as good. Focusing on filling in all the gaps makes your data top-notch.
- Awesome Charts and Graphs: To make really great charts and graphs, you need all the data. Otherwise, the pictures won't tell the real story.
- Keeping Data Tidy: When you have all your data, managing everything is a breeze—no need to spend ages fixing it up later.
- Smart Robots and AI: Cool stuff like AI and machine learning needs all the data to work right. If stuff's missing, the robots might get confused and make mistakes.
- Understanding Your Customers: If you don't have all the info on your customers, you won't really get them. Full data helps you make your customers happier with personalized stuff.
So, wrapping it up, making sure you've got all your data pieces is super important if you want to make smart decisions, understand things better, and generally be awesome at what you're doing. Businesses should totally make sure their data's complete so they can do cool things and keep getting better.
Example of Complete data: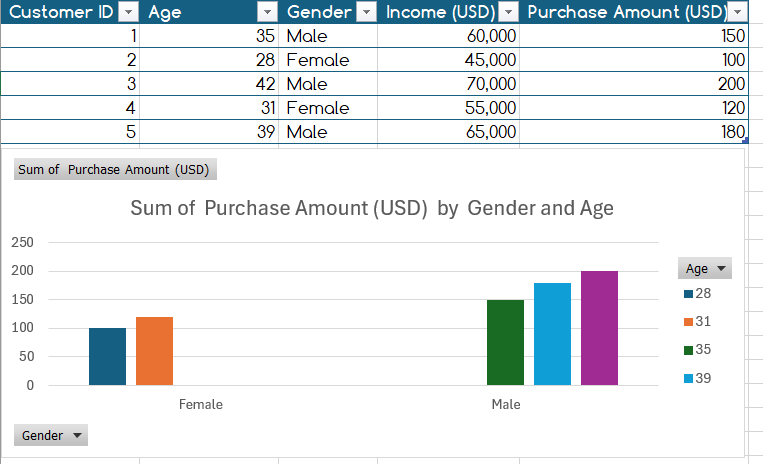
Example of Incomplete data:
**Some Fun Facts:
According to IBM, bad data quality costs the US economy
around $3.1 trillion per year. Such a high figure reflects the sum total of
consequences ranging from incorrect decisions made based on faulty data to
operational inefficiencies.
Research by Gartner has suggested that poor data quality can result in significant costs for businesses, with some estimates claiming organizations might be losing an average of $13 million annually.
A study from MIT indicates that bad data might cost businesses anywhere from 15% to 25% of revenue. For large multinationals, this could translate to losses in the hundreds of millions of dollars.
Experian has noted that on average, organizations believe 28% of their data is inaccurate, which can result in considerable economic losses due to operational inefficiency, customer attrition, or flawed strategies.
Data Warehousing Institute (TDWI) Report: The TDWI report estimates that data quality problems could cost businesses more than $600 billion annually.
It's worth noting these values are estimates of broader economic impacts or averages across surveyed organizations. They serve to represent how vital data quality is to the health of a company.
Data quality or How is missing data affecting the business reports?
The data that any business collects is named raw data. This data is unstructured.
The raw data needs to be interpreted to be useful and to give the insights.
Like people make mistakes, software has bugs, so data has quality problems.
Bad data quality leads to inaccurate reports, insights, and slows the decision making. Bad data quality can cause the economic damage with additional expenses, lost sales, and fines. Not to mention the lack of trust in data.
The criteria for quality data:
- Completeness in the data that is crucial. There should not be any missing information.
- Consistency:
no contradiction or conflict in data (same thing in two or more different
places).
- Timeliness:
is the information available when it is expected?
- Integrity: no missing
links, no orphaned records.
- Accuracy: is the
information reflecting real life values?
- Standardization:
database design should be using common standards or own variations.
Data quality, in my opinion, is one of the most important component of the data, since without the confidence and reliability in the data, no dashboard nor analysis created from that data is useful. Not to mention the efforts put into creating such analysis report.
Data accuracy is the most important criteria for high-quality data. The data must be correct to avoid faulty results. Inaccurate data needs to be identified and fixed.
Maintaining the high-quality data reduces the company’s costs for identifying and correcting the bad data, as well as operational errors and cost of bad decisions.
Therefore, having a high quality in the raw data is very important.
All the tasks to ensure the data has high quality are very valuable for many business stakeholders, management and decision makers.
**Fun fact: by 2025 the global data creation is projected to grow to more than 180 zettabytes. The byte prefixes go like this: each multiplies by 1000 (here talking in metric system, not binary)
- kilo, 1.000 or thousand bytes;
- mega, 1.000.000 or million bytes or 1.000 kilo bytes;
- giga, 1.000.000.000 or 1 billion bytes or 1.000 mega bytes;
- tera, 1.000.000.000.000 or 1 trillion bytes or 1.000 giga bytes;
- peta, 1.000.000.000.000.000 or 1 quadrillion bytes or 1.000 terabytes;
- exa, 1.000.000.000.000.000.000 or 1 quintillion bytes or 1.000 petabytes;
- zetta: 1,000,000,000,000,000,000,000 or 1 sextillion bytes (21 zeros)
- yotta; 1 septillion bytes or 1.000 zettabytes (24 zeros).